

酷狗网址:https://www.kugou.com/yy/rank/home/1-8888.html?from=rank
环境:eclipse+pydev
import requestsfrom bs4 import BeautifulSoup
import time
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36 QIHU 360EE'
} #加入请求头,伪装成浏览器,以便更好抓取数据
def get_info(url): #定义获取信息的函数
wb_data = requests.get(url,headers = headers)
soup = BeautifulSoup(wb_data.text,'lxml')
ranks = soup.select('span.pc_temp_num') #selet()方法见下面图示
titles = soup.select('#rankWrap > div.pc_temp_songlist > ul > li > a')
times = soup.select('span.pc_temp_tips_r > span')
for rank,title,time in zip(ranks,titles,times):
data = {
'rank':rank.get_text().strip(), #歌曲序号
'singer':title.get_text().split('-')[0], #歌手名称
'song':title.get_text().split('-')[1], #歌曲名称
'time':time.get_text().strip() #歌曲时长
}
print (data)
if __name__ == '__main__': #程序主入口
urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'.format(str(i)) for i in range(1,24)] #构建多页url,500条结果需23组,每页网页22条
for url in urls:
get_info(url)
time.sleep(1) #暂停程序,避免因提交网页请求频率过快而导致程序异常终止
select()使用方法:该方法类似于中国>广东省>惠州市,从大到小,提取信息,可通过chrome复制得到,如图示:
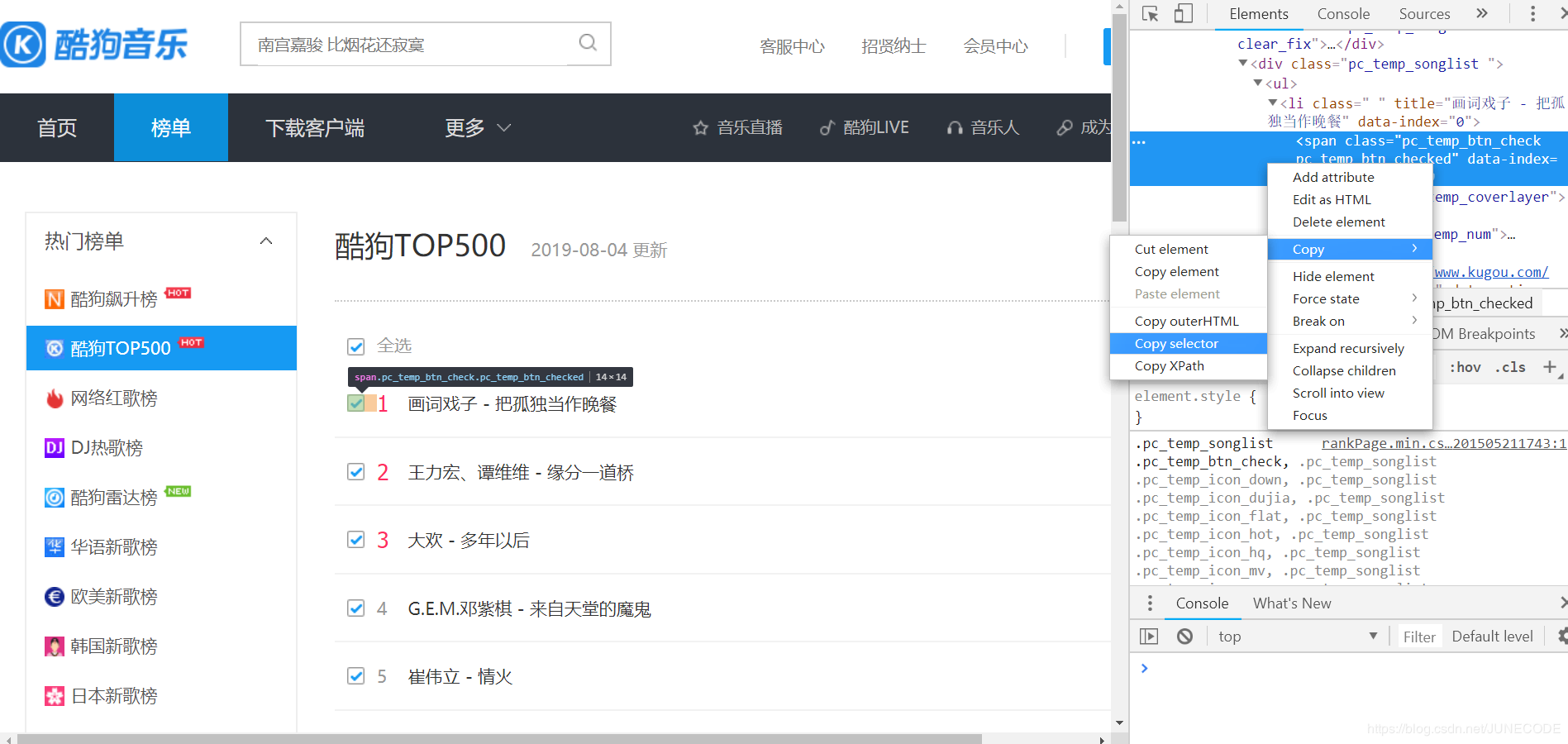
注意:将li:nth-of-child(1)改为li
运行结果:

0% (0)
0% (0)