

OpenCV基础
OpenCV是一个开源的计算机视觉库。提供了很多图像处理常用的工具
批注:本文所有图片数据都在我的GitHub仓库
读取图片并显示
import numpy as npimport cv2 as cvoriginal = cv.imread('../machine_learning_date/forest.jpg')
cv.imshow('Original', original)

显示图片某个颜色通道的图像
blue = np.zeros_like(original)
blue[:, :, 0] = original[:, :, 0] # 0 - 蓝色通道cv.imshow('Blue', blue)
green = np.zeros_like(original)
green[:, :, 1] = original[:, :, 1] # 1 - 绿色通道cv.imshow('Green', green)
red = np.zeros_like(original)
red[:, :, 2] = original[:, :, 2] # 2 - 红色通道cv.imshow('Red', red)



图像剪裁
h, w = original.shape[:2] # (397, 600)l, t = int(w / 4), int(h / 4) # 左上r, b = int(w * 3 / 4), int(h * 3 / 4) # 右下cropped = original[t:b, l:r]
cv.imshow('Cropped', cropped)

图像缩放
cv2.resize(src,dsize,dst=None,fx=None,fy=None,interpolation=None)
参数:
scr:原图
dsize:输出图像尺寸
fx:沿水平轴的比例因子
fy:沿垂直轴的比例因子
interpolation:插值方法
# 输出图像大小=输入图像大小/4scaled1 = cv.resize(original, (int(w / 4), int(h / 4)), interpolation=cv.INTER_LINEAR)
cv.imshow('Scaled1', scaled1)

# 原图像大小,沿x轴,y轴的缩放系数scaled2 = cv.resize(scaled1, None, fx=4, fy=4, interpolation=cv.INTER_LINEAR)
cv.imshow('Scaled2', scaled2)
cv.waitKey() # 等待用户按键触发,或者按 Ese 键 停止等待

图像文件保存
cv.imwrite('../ml_data/blue.jpg', blue)
边缘检测
物体的边缘检测是物体识别常用的手段。边缘检测常用亮度梯度方法。通过识别亮度梯度变化最大的像素点从而检测出物体的边缘。
import cv2 as cv# 读取并展示图像original = cv.imread('../machine_learning_date/chair.jpg', cv.IMREAD_GRAYSCALE)
cv.imshow('Original', original)

索贝尔边缘识别
cv.Sobel(original, cv.CV_64F, 1, 0, ksize=5)
参数:
src:源图像
ddepth:cv.CV_64F:卷积运算使用数据类型为64位浮点型(保证微分的精度)
dx:1表示取水平方向索贝尔偏微分
dy:0表示不取垂直方向索贝尔偏微分
ksize:卷积核为5*5的方阵
水平方向索贝尔偏微分
hsobel = cv.Sobel(original, cv.CV_64F, 1, 0, ksize=5)
cv.imshow('H-Sobel', hsobel)

垂直方向索贝尔偏微分
vsobel = cv.Sobel(original, cv.CV_64F, 0, 1, ksize=5)
cv.imshow('V-Sobel', vsobel)

水平和垂直方向索贝尔偏微分
sobel = cv.Sobel(original, cv.CV_64F, 1, 1, ksize=5)
cv.imshow('Sobel', sobel)

拉普拉斯边缘识别
cv.Laplacian(original, cv.CV_64F)
laplacian = cv.Laplacian(original, cv.CV_64F)
cv.imshow('Laplacian', laplacian)

Canny边缘识别
cv.Canny(original, 50, 240)
image:输入图像
threshold1:50,水平方向阈值
threshold1:240,垂直方向阈值
canny = cv.Canny(original, 50, 80)
cv.imshow('Canny', canny)
cv.waitKey()

亮度提升
OpenCV提供了直方图均衡化的方式实现亮度提升,更有利于边缘识别与物体识别模型的训练。
彩色图转为灰度图
gray = cv.cvtColor(original, cv.COLOR_BGR2GRAY)
直方图均衡化
equalized_gray = cv.equalizeHist(gray)
案例:
读取图像
import cv2 as cv# 读取图片original = cv.imread('../machine_learning_date/sunrise.jpg')
cv.imshow('Original', original) # 显示图片

彩色图转为灰度图
gray = cv.cvtColor(original, cv.COLOR_BGR2GRAY)
cv.imshow('Gray', gray)

灰度图直方图均衡化
equalized_gray = cv.equalizeHist(gray)
cv.imshow('Equalized Gray', equalized_gray)

YUV:亮度,色度,饱和度
yuv = cv.cvtColor(original, cv.COLOR_BGR2YUV)
yuv[..., 0] = cv.equalizeHist(yuv[..., 0]) # 亮度 直方图均衡化yuv[..., 1] = cv.equalizeHist(yuv[..., 1]) # 色度 直方图均衡化yuv[..., 2] = cv.equalizeHist(yuv[..., 2]) # 饱和度 直方图均衡化equalized_color = cv.cvtColor(yuv, cv.COLOR_YUV2BGR)
cv.imshow('Equalized Color', equalized_color)
cv.waitKey()

角点检测
平直棱线的交汇点(颜色梯度方向改变的像素点的位置)
Harris角点检测器
gray = cv.cvtColor(original, cv.COLOR_BGR2GRAY)
corners = cv.cornerHarris(gray, 7, 5, 0.04)
src:输入单通道8位或浮点图像。
blockSize:角点检测区域大小
ksize:Sobel求导中使用的窗口大小
k:边缘线方向改变超过阈值0.04弧度即为一个角点,一般取[0.04 0.06]
案例:
import cv2 as cv
original = cv.imread('../machine_learning_date/box.png')
cv.imshow('Original', original)
gray = cv.cvtColor(original, cv.COLOR_BGR2GRAY) # 转换成灰度,减少计算量cv.imshow('Gray', gray)
corners = cv.cornerHarris(gray, 7, 5, 0.04) # Harris角点检测器# 图像混合mixture = original.copy()
mixture[corners > corners.max() * 0.01] = [0, 0, 255] # BGR [0, 0, 255]变红cv.imshow('Corner', mixture)
cv.waitKey()
图像识别
特征点检测
常用特征点检测有:STAR特征点检测 / SIFT特征点检测
特征点检测结合了 边缘检测 与 角点检测 从而识别出图形的特征点
STAR特征点检测相关API如下:
star = cv.xfeatures2d.StarDetector_create() # 创建STAR特征点检测器
keypoints = star.detect(gray) # 检测出gray图像所有的特征点
把所有的特征点绘制在mixture图像中
cv.drawKeypoints(original, keypoints, mixture, flags=cv.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
参数:
image:原图片
keypoints:源图像中的关键点
outImage:输出图片
flags:标志设置图形特征
案例:
import cv2 as cv
original = cv.imread('../machine_learning_date/table.jpg')
gray = cv.cvtColor(original, cv.COLOR_BGR2GRAY) # 变成灰度图,减少计算cv.imshow('Gray', gray)
star = cv.xfeatures2d.StarDetector_create() # 创建STAR特征点检测器keypoints = star.detect(gray) # 检测出gray图像所有的特征点mixture = original.copy()# drawKeypoints方法可以把所有的特征点绘制在mixture图像中cv.drawKeypoints(original, keypoints, mixture,
flags=cv.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv.imshow('Mixture', mixture)
cv.waitKey()


SIFT特征点检测相关API:
sift = cv.xfeatures2d.SIFT_create() # 创建SIFT特征点检测器
keypoints = sift.detect(gray) # 检测出gray图像所有的特征点
案例:
import cv2 as cv
original = cv.imread('../machine_learning_date/table.jpg')
gray = cv.cvtColor(original, cv.COLOR_BGR2GRAY)
cv.imshow('Gray', gray)
sift = cv.xfeatures2d.SIFT_create() # 创建SIFT特征点检测器keypoints = sift.detect(gray) # 检测出gray图像所有的特征点mixture = original.copy()# 把所有的特征点绘制在mixture图像中cv.drawKeypoints(original, keypoints, mixture,
flags=cv.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv.imshow('Mixture', mixture)
cv.waitKey()


特征值矩阵
图像特征值矩阵(描述)记录了图像的特征点以及每个特征点的梯度信息,相似图像的特征值矩阵也相似。这样只要有足够多的样本,就可以基于隐马尔科夫模型进行图像内容的识别。
特征值矩阵相关API:
sift = cv.xfeatures2d.SIFT_create() keypoints = sift.detect(gray) _, desc = sift.compute(gray, keypoints)
案例:
import cv2 as cvimport matplotlib.pyplot as plt
original = cv.imread('../machine_learning_date/table.jpg')
gray = cv.cvtColor(original, cv.COLOR_BGR2GRAY)
cv.imshow('Gray', gray)
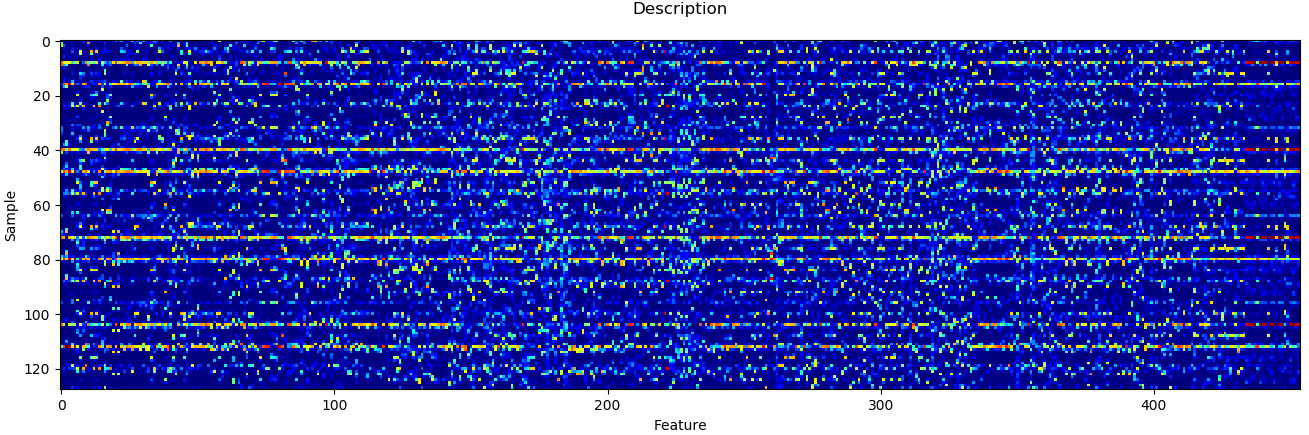
sift = cv.xfeatures2d.SIFT_create() # 创建SIFT特征点检测器keypoints = sift.detect(gray) # 检测出gray图像所有的特征点_, desc = sift.compute(gray, keypoints)print(desc.shape) # (454, 128)plt.matshow(desc.T, cmap='jet', fignum='Description')
plt.title('Description')
plt.xlabel('Feature')
plt.ylabel('Sample')
plt.tick_params(which='both', top=False, labeltop=False, labelbottom=True, labelsize=10)
plt.show()
物体识别
1、读取training文件夹中的训练图片样本,每个图片对应一个desc矩阵,每个desc都有一个类别(car)
2、把所有类别为car的desc合并在一起,形成训练集
| desc | | | desc | car | | desc | | .....
由上述训练集样本可以训练一个用于匹配car的HMM。
3、训练3个HMM分别对应每个物体类别。 保存在列表中。
4、读取testing文件夹中的测试样本,整理测试样本
| desc | car | | desc | moto |
5、针对每一个测试样本:
分别使用3个HMM模型,对测试样本计算score得分。
取3个模型中得分最高的模型所属类别作为预测类别。
import osimport numpy as npimport cv2 as cvimport hmmlearn.hmm as hldef search_files(directory):
directory = os.path.normpath(directory)
objects = {}for curdir, subdirs, files in os.walk(directory):for file in files:if file.endswith('.jpg'):
label = curdir.split(os.path.sep)[-1]if label not in objects:
objects[label] = []
path = os.path.join(curdir, file)
objects[label].append(path)return objects# 加载训练集样本数据,训练模型,模型存储train_objects = search_files('../machine_learning_date/objects/training')
train_x, train_y = [], []for label, filenames in train_objects.items():
descs = np.array([])for filename in filenames:
image = cv.imread(filename)
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)# 范围缩放,使特征描述矩阵样本数量一致h, w = gray.shape[:2]
f = 200 / min(h, w)
gray = cv.resize(gray, None, fx=f, fy=f)
sift = cv.xfeatures2d.SIFT_create() # 创建SIFT特征点检测器keypoints = sift.detect(gray) # 检测出gray图像所有的特征点_, desc = sift.compute(gray, keypoints) # 转换成特征值矩阵if len(descs) == 0:
descs = descelse:
descs = np.append(descs, desc, axis=0)
train_x.append(descs)
train_y.append(label)
models = {}for descs, label in zip(train_x, train_y):
model = hl.GaussianHMM(n_components=4, covariance_type='diag', n_iter=100)
models[label] = model.fit(descs)# 测试模型test_objects = search_files('../machine_learning_date/objects/testing')
test_x, test_y = [], []for label, filenames in test_objects.items():
descs = np.array([])for filename in filenames:
image = cv.imread(filename)
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
sift = cv.xfeatures2d.SIFT_create()
keypoints = sift.detect(gray)
_, desc = sift.compute(gray, keypoints)if len(descs) == 0:
descs = descelse:
descs = np.append(descs, desc, axis=0)
test_x.append(descs)
test_y.append(label)# 遍历所有测试样本 使用model匹配测试样本查看每个模型的匹配分数pred_y = []for descs, test_label in zip(test_x, test_y):
best_score, best_label = None, Nonefor pred_label, model in models.items():
score = model.score(descs)if (best_score == None) or (best_score < score):
best_score = score
best_label = pred_labelprint(test_label, '->', pred_label, score)# airplane -> airplane -373374.23370679974# airplane -> car -374022.20182585815# airplane -> motorbike -374127.46289302857# car -> airplane -163638.3153800373# car -> car -163691.52001099114# car -> motorbike -164410.0557508754# motorbike -> airplane -467472.6294620241# motorbike -> car -470149.6143097087# motorbike -> motorbike -464606.0040570249 pred_y.append(best_label)print(test_y) # ['airplane', 'car', 'motorbike']print(pred_y) # ['airplane', 'airplane', 'motorbike']
人脸识别
人脸识别与图像识别的区别在于人脸识别需要识别出两个人的不同点。
视频捕捉
通过OpenCV访问视频捕捉设备(视频头),从而获取图像帧。
视频捕捉相关API:
import cv2 as cv# 获取视频捕捉设备video_capture = cv.VideoCapture(0)# 读取一帧frame = video_capture.read()[1]
cv.imshow('VideoCapture', frame)# 释放视频捕捉设备video_capture.release()# 销毁cv的所有窗口cv.destroyAllWindows()
案例:
import cv2 as cv# 获取视频捕获设备video_capture = cv.VideoCapture(0)# 读取一帧while True:
frame = video_capture.read()[1]
cv.imshow('frame', frame)# 每隔33毫秒自动更新图像if cv.waitKey(33) == 27: # 退出键是27(Esc)breakvideo_capture.release()
cv.destroyAllWindows()
人脸定位
哈尔级联人脸定位
import cv2 as cv# 通过特征描述文件构建哈尔级联人脸识别器fd = cv.CascadeClassifier('../data/haar/face.xml')# 从一个图像中识别出所有的人脸区域# 1.3:为最小的人脸尺寸# 5:最多找5张脸# 返回:# faces: 抓取人脸(矩形区域)列表 [(l,t,w,h),(),()..]faces = fd.detectMultiScale(frame, 1.3, 5)
face = faces[0] # 第一张脸# 绘制椭圆cv.ellipse(
frame, # 图像(l + a, t + b), # 椭圆心(a, b), # 半径0, # 椭圆旋转角度0, 360, # 起始角, 终止角(255, 0, 255), # 颜色2 # 线宽)
案例:
import cv2 as cv# 哈尔级联人脸定位器fd = cv.CascadeClassifier('../../data/haar/face.xml')
ed = cv.CascadeClassifier('../../data/haar/eye.xml')
nd = cv.CascadeClassifier('../../data/haar/nose.xml')
vc = cv.VideoCapture(0)while True:
frame = vc.read()[1]
faces = fd.detectMultiScale(frame, 1.3, 5)for l, t, w, h in faces:
a, b = int(w / 2), int(h / 2)
cv.ellipse(frame, (l + a, t + b), (a, b), 0, 0, 360, (255, 0, 255), 2)
face = frame[t:t + h, l:l + w]
eyes = ed.detectMultiScale(face, 1.3, 5)for l, t, w, h in eyes:
a, b = int(w / 2), int(h / 2)
cv.ellipse(face, (l + a, t + b), (a, b), 0, 0, 360, (0, 255, 0), 2)
noses = nd.detectMultiScale(face, 1.3, 5)for l, t, w, h in noses:
a, b = int(w / 2), int(h / 2)
cv.ellipse(face, (l + a, t + b), (a, b), 0, 0, 360, (0, 255, 255), 2)
cv.imshow('VideoCapture', frame)if cv.waitKey(33) == 27:breakvc.release()
cv.destroyAllWindows()
人脸识别
简单人脸识别:OpenCV的LBPH(局部二值模式直方图)
读取样本图片数据,整理图片的路径列表
读取每张图片,基于haar裁剪每张人脸,把人脸数据放入train_x,作为训练数据。在整理train_y时,由于Bob、Sala、Roy是字符串,需要把字符串做一个标签编码 LabelEncoder
遍历训练集,把训练集交给LBPH人脸识别模型进行训练。
读取测试集数据,整理图片的路径列表
遍历每张图片,把图片中的人脸使用相同的方式裁剪,把人脸数据交给LBPH模型进行类别预测,得到预测结果。
以图像的方式输出结果。
# -*- coding: utf-8 -*-import osimport numpy as npimport cv2 as cvimport sklearn.preprocessing as sp
fd = cv.CascadeClassifier('../machine_learning_date/haar/face.xml')def search_faces(directory):
directory = os.path.normpath(directory)
faces = {}for curdir, subdirs, files in os.walk(directory):for jpeg in (file for file in files if file.endswith('.jpg')):
path = os.path.join(curdir, jpeg)
label = path.split(os.path.sep)[-2]if label not in faces:
faces[label] = []
faces[label].append(path)return faces
train_faces = search_faces('../machine_learning_date/faces/training')
codec = sp.LabelEncoder()
codec.fit(list(train_faces.keys()))
train_x, train_y = [], []for label, filenames in train_faces.items():for filename in filenames:
image = cv.imread(filename)
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
faces = fd.detectMultiScale(gray, 1.1, 2, minSize=(100, 100))for l, t, w, h in faces:
train_x.append(gray[t:t + h, l:l + w])
train_y.append(codec.transform([label])[0])
train_y = np.array(train_y)'''训练集结构:
train_x train_y
-------------------
| face | 0 |
-------------------
| face | 1 |
-------------------
| face | 2 |
-------------------
| face | 1 |
-------------------'''# 局部二值模式直方图人脸识别分类器model = cv.face.LBPHFaceRecognizer_create()
model.train(train_x, train_y)# 测试test_faces = search_faces('../ml_data/faces/testing')
test_x, test_y, test_z = [], [], []for label, filenames in test_faces.items():for filename in filenames:
image = cv.imread(filename)
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
faces = fd.detectMultiScale(gray, 1.1, 2, minSize=(100, 100))for l, t, w, h in faces:
test_x.append(gray[t:t + h, l:l + w])
test_y.append(codec.transform([label])[0])
a, b = int(w / 2), int(h / 2)
cv.ellipse(image, (l + a, t + b), (a, b), 0, 0, 360, (255, 0, 255), 2)
test_z.append(image)
test_y = np.array(test_y)
pred_test_y = []for face in test_x:
pred_code = model.predict(face)[0]
pred_test_y.append(pred_code)print(codec.inverse_transform(test_y))print(codec.inverse_transform(pred_test_y))
escape = Falsewhile not escape:for code, pred_code, image in zip(test_y, pred_test_y, test_z):
label, pred_label = codec.inverse_transform([code, pred_code])
text = '{} {} {}'.format(label, '==' if code == pred_code else '!=', pred_label)
cv.putText(image, text, (10, 60), cv.FONT_HERSHEY_SIMPLEX, 2, (255, 255, 255), 6)
cv.imshow('Recognizing...', image)if cv.waitKey(1000) == 27:
escape = Truebreak