

ElasticSearch Java API 入门教程
目录
说明
萌新第一次写博客,写得不好的地方见谅,没人看得懂的话也就自己需要的时候来参考一下了。
博客园的markdown和有道云笔记还是有区别的,有序列表不能接空格,支持的目录级数也不多。
本文基于elasticsearch-6.1.1版本,本文内容与elasticsearch java api官网一致
maven
elasticsearch需要的jar包:
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>transport</artifactId> <version>6.1.1</version> </dependency>
log4j2需要的jar包:
<dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.9.1</version> </dependency>
日志准备
src/resource/log4j2.properties
appender.console.type = Console
appender.console.name = console
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = [%d{ISO8601}][%-5p][%-25c] %marker%m%n
rootLogger.level = info
rootLogger.appenderRef.console.ref = console
log4j2在类里面的使用
import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; Logger log=LogManager.getLogger(ESServiceImpl.class);
也可以使用其他日志,详见使用其它日志
Client
elseaticSearch java有2种客户端:TransportClient和RestClient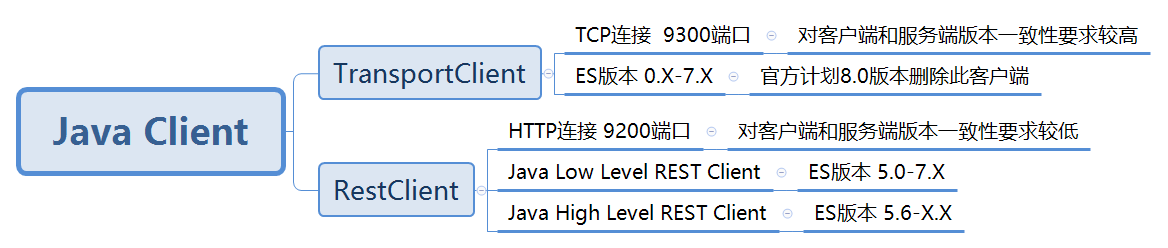
这里推荐使用RestClient,因为TransportClient在es后面的版本可能会被废弃,RestClien的官方API在这里,RestClient也分为Java High Level REST Client和Java Low Level REST Client,它们的区别:
Low Client很完善,支持RESTful
High Client基于Low Client,封装了常用的API,但是还是不够完善,需要增加API,对版本要求很高
从TransportClient迁徙的话,首选High Client,因为API接收参数和返回值和TransportClient是一样的
这里我们使用Java High Level REST Client
Java High Level REST Client
特点
基于Java Low REST Client。它的主要目标是公开API特定的方法,接受请求对象作为参数并返回响应对象,以便客户端本身处理请求编组和响应非编组。
客户端是向前兼容的,这意味着它支持与Elasticsearch的更高版本进行通信。比如6.0客户端能够与任何6.x Elasticsearch节点通信,所以升级先升级节点,再升级客户端(Client)。打个比方,HighClient客户端是6.2版本,节点6.2、6.3、6.4都有,现在要将他们都升级到6.4,先升级客户端的话,6.4的客户端可能不支持节点6.3版本的API
入门
需要jdk8+,配置maven仓库
<dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>6.1.1</version> </dependency> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-client</artifactId> <version>6.1.1</version> </dependency> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>6.1.1</version> </dependency>
可能无法解析客户端的Lucene依赖关系。
<repository> <id>elastic-lucene-snapshots</id> <name>Elastic Lucene Snapshots</name> <url>http://s3.amazonaws.com/download.elasticsearch.org/lucenesnapshots/00142c9</url> <releases><enabled>true</enabled></releases> <snapshots><enabled>false</enabled></snapshots> </repository>
连接工具类ElasticSearchTools
//创建连接工具类
public class ElasticSearchTools {
public static RestHighLevelClient client=null;
public final static String HOST = "192.168.22.128"; //服务器部署
public final static Integer PORT = 9201; //端口
public static RestHighLevelClient getClientConnection(){
//client = new RestHighLevelClient(RestClient.builder(new HttpHost(HOST, 9200, "http"), new HttpHost(HOST, PORT, "http")));
client = new RestHighLevelClient(
RestClient.builder(new HttpHost(new HttpHost(HOST, PORT, "http"))));
return client;
}
public static void closeClientConnection(RestHighLevelClient client) throws IOException {
client.close();
}
//在工具类里面定义一个写日志的静态方法
public static void logInfo(Logger log,String message) {
if(log.isInfoEnabled()){
log.info(message);
}
}
}
索引API
删除索引
public boolean deleteIndexAPI(String index)throws IOException {
RestHighLevelClient client = ElasticSearchTools.getClientConnection();
DeleteIndexRequest request = new DeleteIndexRequest(index);
//删除超时时间,推荐使用前者,最好不要使用魔法变量,便于理解和维护
request.timeout(TimeValue.timeValueMinutes(2)); //request.timeout("2m");
//连接到主节点的时间
request.masterNodeTimeout(TimeValue.timeValueMinutes(1));
// request.masterNodeTimeout("1m");
//设置如何解析不可用的索引
request.indicesOptions(IndicesOptions.lenientExpandOpen());
//flag,用来查看结果、返回
boolean acknowledged=false;
//删除
DeleteIndexResponse deleteIndexResponse;
try {
deleteIndexResponse = client.indices().deleteIndex(request);
//是否所有节点都已删除该索引
acknowledged = deleteIndexResponse.isAcknowledged();
}catch (ElasticsearchException e) {
if (e.status() == RestStatus.NOT_FOUND) {
ElasticSearchTools.logInfo(log, "Index "+index+" Not Found");
}
}catch (Exception e) {
e.printStackTrace();
}finally {
//关闭客户端
ElasticSearchTools.closeClientConnection(client);
}
return acknowledged;
}
如果执行时间较长,使用异步删除
client.indices().deleteIndexAsync(request, new ActionListener<DeleteIndexResponse>() {
@Override
public void onResponse(DeleteIndexResponse deleteIndexResponse) {
boolean acknowledged = deleteIndexResponse.isAcknowledged();
if(acknowledged) {
ElasticSearchTools.logInfo(log, "Success delete Index:"+index);
}else {
ElasticSearchTools.logInfo(log, "Failed delete Index:"+index);
}
}
@Override
public void onFailure(Exception e) {
if(e instanceof ElasticsearchException) {
if (((ElasticsearchException) e).status() == RestStatus.NOT_FOUND) {
ElasticSearchTools.logInfo(log, "Index "+index+" Not Found");
}
}
}
});
单个文档API
创建文档API----INDEX
public void indexAPI(Elastic es)throws IOException {
RestHighLevelClient client = ElasticSearchTools.getClientConnection();
IndexRequest request = new IndexRequest(es.get_index(),es.get_type(),es.get_id()).source(es.get_resource());
//超时时间
request.timeout(TimeValue.timeValueSeconds(1));
//乐观锁版本控制,create操作不支持
//request.version(2);
//刷新策略
request.setRefreshPolicy(WriteRequest.RefreshPolicy.WAIT_UNTIL);
//操作类型:create创建文档,index创建、更新都可以
request.opType(DocWriteRequest.OpType.INDEX);
try {
IndexResponse indexResponse = client.index(request);
if(indexResponse.getResult()==DocWriteResponse.Result.CREATED) {
//识别本次的操作是create
ElasticSearchTools.logInfo(log,
"create document:"+indexResponse.getId()+",and now_version is :"+indexResponse.getVersion());
}else if(indexResponse.getResult()==DocWriteResponse.Result.UPDATED) {
//识别本次的操作是update
ElasticSearchTools.logInfo(log,
"update document:"+indexResponse.getId()+",and now_version is :"+indexResponse.getVersion());
}
ReplicationResponse.ShardInfo shards = indexResponse.getShardInfo();
if (shards.getTotal() != shards.getSuccessful()) {
ElasticSearchTools.logInfo(log,"分片备份不完全");
}
} catch (ElasticsearchException e) {
//冲突异常,操作时version与服务器不一致
//create一个已有文档时
if(e.status() == RestStatus.CONFLICT) {
ElasticSearchTools.logInfo(log,"操作冲突!!!!!");
}
}catch (Exception e) {
e.printStackTrace();
}finally {
ElasticSearchTools.closeClientConnection(client);
}
}
注意:index操作有更新的功能,但是这里的更新是全部更新,不是匹配到的字段才更新,是一个完全替代的效果,相当于把原来的删除了,再去创建一个。同样有异步操作,和上面delete类似
结果测试
update document:2,and now_version is :3
根据id查找文档--GET
1.文档特定存储字段的搜索,像下面age这种设置了store:true的字段
{
"mappings": {
"doc":{
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer",
"store": true
},
"address":{
"type": "text",
"fields": {
"keyword":{
"type": "keyword"
}
}
}
}
}
}
public String getIndexAPI(Elastic es)throws IOException {
RestHighLevelClient client = ElasticSearchTools.getClientConnection();
GetRequest request = new GetRequest(es.get_index(), es.get_type(), es.get_id());
//在检索文档之前执行刷新,默认false
request.refresh(true);
//要查找文档的存储字段
request.storedFields("age");
GetResponse getResponse = null;
try {
getResponse = client.get(request);
ElasticSearchTools.logInfo(log,getResponse.toString());
}catch (ElasticsearchException e) {
if (e.status() == RestStatus.NOT_FOUND) {
ElasticSearchTools.logInfo(log,"Index Not Found");
}
}catch (Exception e) {
e.printStackTrace();
}finally {
ElasticSearchTools.closeClientConnection(client);
}
ElasticSearchTools.logInfo(log,getResponse.getFields().toString());
return null;
}
这样搜索出来只能显示查找结果和指定的存储字段属性,其它属性不能显示
{"_index":"zhangsun","_type":"doc","_id":"2","_version":1,"found":true,"fields":{"age":[22]}}
{age=DocumentField{name='age', values=[22]}}
2.还有一种方法就是使用FetchSourceContext查找
public String getIndexAPI(Elastic es) throws IOException {
RestHighLevelClient client = ElasticSearchTools.getClientConnection();
GetRequest request = new GetRequest(es.get_index(), es.get_type(), es.get_id());
//要查找的文档字段,支持匹配
String[] includes = new String[]{"name", "*ress"};
String[] excludes = Strings.EMPTY_ARRAY;
//true和false表示是否查询_source里面的字段,includes/excludes表示为true时查询/不查询的字段
FetchSourceContext fetchSourceContext = new FetchSourceContext(true,includes, excludes);
request.fetchSourceContext(fetchSourceContext);
// 在检索文档之前执行刷新,默认false
request.refresh(true);
//指定版本号才能查询,否则报错RestStatus.CONFLICT
//request.version(1);
GetResponse getResponse = null;
String sourceAsString = null;
try {
getResponse = client.get(request);
if(getResponse.isExists()) {
ElasticSearchTools.logInfo(log,getResponse.toString());
//将查询的_source里面的字段转化为json字符串,上面设置了false的话会出现NPE
sourceAsString = getResponse.getSourceAsString();
ElasticSearchTools.logInfo(log,sourceAsString);
//将查询的_source里面的字段转化为map,上面设置了false的话会出现NPE
Map<String, Object> sourceAsMap = getResponse.getSourceAsMap();
ElasticSearchTools.logInfo(log,sourceAsMap.toString());
}
} catch (ElasticsearchException e) {
if (e.status() == RestStatus.NOT_FOUND) {
ElasticSearchTools.logInfo(log, "Index Not Found");
}else if (e.status() == RestStatus.CONFLICT) {
ElasticSearchTools.logInfo(log, "Version Not Match");
}
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}finally {
ElasticSearchTools.closeClientConnection(client);
}
return null;
}
正常查询结果:
{"_index":"zhangsun","_type":"doc","_id":"2","_version":2,"found":true,"_source":{"address":"zhans guh hahaha jks dhjfs","name":"hjl"}}
{"address":"zhans guh hahaha jks dhjfs","name":"hjl"}
{address=zhans guh hahaha jks dhjfs, name=hjl}
==查找也有异步操作方法,原理同上==
删除文档--DELETE
public String deleteDocumentAPI(Elastic es) throws IOException {
RestHighLevelClient client = ElasticSearchTools.getClientConnection();
DeleteRequest request = new DeleteRequest(es.get_index(), es.get_type(), es.get_id());
request.timeout(TimeValue.timeValueMinutes(2));
//刷新策略
request.setRefreshPolicy(WriteRequest.RefreshPolicy.WAIT_UNTIL);
//request.version(2);
try {
DeleteResponse deleteResponse = client.delete(request);
ElasticSearchTools.logInfo(log, deleteResponse.toString());
//没找到文档不会报错,会将result的值设为not_found
if (deleteResponse.getResult() == DocWriteResponse.Result.NOT_FOUND) {
ElasticSearchTools.logInfo(log, "Document Not Found");
}
//分片信息
ReplicationResponse.ShardInfo shardInfo = deleteResponse.getShardInfo();
//处理成功分片数小于总分片数的情况
if (shardInfo.getTotal() != shardInfo.getSuccessful()) {
ElasticSearchTools.logInfo(log, "Shards Error");
}
//处理分片的失败
if (shardInfo.getFailed() > 0) {
for (ReplicationResponse.ShardInfo.Failure failure : shardInfo.getFailures()) {
String reason = failure.reason();
ElasticSearchTools.logInfo(log, "Shards Error"+reason);
}
}
} catch (ElasticsearchException e) {
//同样删除时版本问题
if (e.status() == RestStatus.CONFLICT) {
ElasticSearchTools.logInfo(log, "Version Not Match");
}
e.printStackTrace();
}finally {
ElasticSearchTools.closeClientConnection(client);
}
return null;
}
测试结果(出现Shards Error的原因是因为我只启动了集群中的一个ES实例,Index的primary shards在本节点上,而replica shard始终是UNASSIGNED,这是集群健康状态也是yellow)
DeleteResponse[index=zhangsun,type=doc,id=2,version=3,result=deleted,shards=ShardInfo{total=2, successful=1, failures=[]}]
Shards Error
更新文档--UPDATE
1.使用脚本script方式更新:
public String updateDocumentAPI(Elastic es) throws IOException {
RestHighLevelClient client = ElasticSearchTools.getClientConnection();
UpdateRequest request = new UpdateRequest(es.get_index(), es.get_type(), es.get_id());
request.retryOnConflict(3); //多用户在同时更新的时候会造成冲突,设置重试次数
request.timeout(TimeValue.timeValueSeconds(1));
request.setRefreshPolicy(WriteRequest.RefreshPolicy.WAIT_UNTIL);
//request.version(2); 不能和request.retryOnConflict共存
//设置一个key和value都是final的Map
Map<String, Object> parameters = Collections.singletonMap("count", 4);
request.script(inline);
try {
UpdateResponse updateResponse = client.update(request);
if (updateResponse.getResult() == DocWriteResponse.Result.CREATED) {
ElasticSearchTools.logInfo(log, "Document create operation");
} else if (updateResponse.getResult() == DocWriteResponse.Result.UPDATED) {
ElasticSearchTools.logInfo(log, "Document update operation");
}else if (updateResponse.getResult() == DocWriteResponse.Result.NOOP) {
ElasticSearchTools.logInfo(log, "The Same as Last Version,Nothing Done");
}
//分片状态判断这里就不写了,和前面一样
} catch (ElasticsearchException e) {
if (e.status() == RestStatus.NOT_FOUND) {
ElasticSearchTools.logInfo(log, "Document Not Found");
}
if (e.status() == RestStatus.CONFLICT) {
ElasticSearchTools.logInfo(log, "Version Not Match");
}
e.printStackTrace();
}catch (Exception e) {
e.printStackTrace();
}finally {
ElasticSearchTools.closeClientConnection(client);
}
return null;
}
这段脚本的功能相当于:(==inline==在es6.x已经废弃了,使用source替代)
POST /zhangsun/doc/2/_update
{
"script": {
"inline": "ctx._source.age += params.count",
"params": {
"count":4
}
}
}
2.使用doc方式更新
public String updateDocumentAPI(Elastic es) throws IOException {
RestHighLevelClient client = ElasticSearchTools.getClientConnection();
UpdateRequest request = new UpdateRequest(es.get_index(), es.get_type(), es.get_id());
request.retryOnConflict(3); //多用户在同时更新的时候会造成冲突,设置重试次数
request.timeout(TimeValue.timeValueSeconds(1));
request.setRefreshPolicy(WriteRequest.RefreshPolicy.WAIT_UNTIL);
//request.version(2); 不能和request.retryOnConflict共存
request.doc(es.get_resource());//内容就是下面这个param,更多数据形式参考官网
//Map<String,Object> param=new HashMap<String, Object>();
//param.put("name", "zhansgun");
//param.put("address", "China SiChaun");
//让doc操作更新时,没有文档时可以创建一个
request.docAsUpsert(true);
try {
UpdateResponse updateResponse = client.update(request);
ElasticSearchTools.logInfo(log, updateResponse.toString());
if (updateResponse.getResult() == DocWriteResponse.Result.CREATED) {
ElasticSearchTools.logInfo(log, "Document create operation");
} else if (updateResponse.getResult() == DocWriteResponse.Result.UPDATED) {
ElasticSearchTools.logInfo(log, "Document update operation");
}else if (updateResponse.getResult() == DocWriteResponse.Result.NOOP) {
ElasticSearchTools.logInfo(log, "The Same as Last Version,Nothing Done");
}
//分片状态判断这里就不写了,和前面一样
} catch (ElasticsearchException e) {
if (e.status() == RestStatus.NOT_FOUND) {
ElasticSearchTools.logInfo(log, "Document Not Found");
}
if (e.status() == RestStatus.CONFLICT) {
ElasticSearchTools.logInfo(log, "Version Not Match");
}
e.printStackTrace();
}catch (Exception e) {
e.printStackTrace();
}finally {
ElasticSearchTools.closeClientConnection(client);
}
return null;
}
异步++
多个文档API
bulk批量操作
public String bulkAPI(Elastic es) throws IOException {
RestHighLevelClient client = ElasticSearchTools.getClientConnection();
BulkRequest request = new BulkRequest();
//删除id=1
request.add(new DeleteRequest(es.get_index(), es.get_type(), "1"));
//局部更新id=2
request.add(new UpdateRequest(es.get_index(), es.get_type(), "2")
.doc(XContentType.JSON,"address", "NanChong","name", "hahhahahha"));
//创建id=4,存在则先删除再创建,完全替代
request.add(new IndexRequest(es.get_index(), es.get_type(), "4")
.source(XContentType.JSON,"field", "baz"));
request.timeout(TimeValue.timeValueMinutes(2));
request.setRefreshPolicy(WriteRequest.RefreshPolicy.WAIT_UNTIL);
request.waitForActiveShards(ActiveShardCount.ALL);
try {
BulkResponse bulkResponse = client.bulk(request);
//输出每个操作的结果
for (BulkItemResponse bulkItemResponse : bulkResponse) {
DocWriteResponse itemResponse = bulkItemResponse.getResponse();
if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.INDEX
|| bulkItemResponse.getOpType() == DocWriteRequest.OpType.CREATE) {
IndexResponse indexResponse = (IndexResponse) itemResponse;
ElasticSearchTools.logInfo(log, "The Operation is Index,And the Result is:"+indexResponse.toString());
} else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.UPDATE) {
UpdateResponse updateResponse = (UpdateResponse) itemResponse;
ElasticSearchTools.logInfo(log, "The Operation is Update,And the Result is:"+updateResponse.toString());
} else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.DELETE) {
DeleteResponse deleteResponse = (DeleteResponse) itemResponse;
ElasticSearchTools.logInfo(log, "The Operation is Delete,And the Result is:"+deleteResponse.toString());
}
}
//判断批操作是否有错误
if (bulkResponse.hasFailures()) {
ElasticSearchTools.logInfo(log,"There are At Least One Error Occured:");
for (BulkItemResponse bulkItemResponse : bulkResponse) {
if (bulkItemResponse.isFailed()) {
BulkItemResponse.Failure failure = bulkItemResponse.getFailure();
ElasticSearchTools.logInfo(log,failure.toString());
}
}
}
//分片状态判断这里就不写了,和前面一样
} catch (ElasticsearchException e) {
if (e.status() == RestStatus.NOT_FOUND) {
ElasticSearchTools.logInfo(log, "Document Not Found");
}
e.printStackTrace();
}catch (Exception e) {
e.printStackTrace();
}finally {
ElasticSearchTools.closeClientConnection(client);
}
return null;
}
The Operation is Delete,And the Result is:DeleteResponse[index=zhangsun,type=doc,id=1,version=2,result=deleted,shards=xxx]
The Operation is Update,And the Result is:UpdateResponse[index=zhangsun,type=doc,id=2,version=17,seqNo=27,primaryTerm=1,result=updated,shards=xxx]
The Operation is Update,And the Result is:UpdateResponse[index=zhangsun,type=doc,id=2,version=18,seqNo=28,primaryTerm=1,result=updated,shards=xxx]
The Operation is Index,And the Result is:IndexResponse[index=zhangsun,type=doc,id=4,version=1,result=created,seqNo=29,primaryTerm=1,shards=xxx]
bulk的API还配置有监听器BulkProcessor.Listener处理每个操作执行前后需要处理的内容
同样,异步操作++
查找API
searchAPI
1.普通匹配查询
public String searchAPI(Elastic es) throws IOException {
RestHighLevelClient client = ElasticSearchTools.getClientConnection();
SearchRequest searchRequest = new SearchRequest(es.get_index()).types(es.get_type());
searchRequest.preference("_local");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//查找全部
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//精准匹配,使用keyword格式,因为text格式会分词
//searchSourceBuilder.query(QueryBuilders.termQuery("address.keyword", "sichuan nanchong"));
//模糊匹配,空格表示或
//searchSourceBuilder.query(QueryBuilders.matchQuery("address", "sichaun nanchong"));
//匹配短语
//searchSourceBuilder.query(QueryBuilders.matchPhraseQuery("address", "sichuan nanchong"));
searchSourceBuilder.from(0);
searchSourceBuilder.size(5);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//结果排序
searchSourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC));//按照score降序排序
searchSourceBuilder.sort(new FieldSortBuilder("age").order(SortOrder.ASC));
//开启搜索_source里面的内容
searchSourceBuilder.fetchSource(true);
//需要过滤的属性
String[] includeFields = new String[] {"name", "address"};
String[] excludeFields = new String[] {"age"};
searchSourceBuilder.fetchSource(includeFields, excludeFields);
//关联SearchSourceBuilder
searchRequest.source(searchSourceBuilder);
//搜索
SearchResponse searchResponse;
try {
searchResponse = client.search(searchRequest);
//状态结果
RestStatus status = searchResponse.status();
TimeValue took = searchResponse.getTook();
Boolean terminatedEarly = searchResponse.isTerminatedEarly();
boolean timedOut = searchResponse.isTimedOut();
ElasticSearchTools.logInfo(log, "状态码:"+status.toString()+"花费时间:"+took+"请求提前终止:"+terminatedEarly+"超时:"+timedOut);
//分片情况
//int totalShards = searchResponse.getTotalShards();
//int successfulShards = searchResponse.getSuccessfulShards();
//int failedShards = searchResponse.getFailedShards();
//for (ShardSearchFailure failure : searchResponse.getShardFailures()) {
// failures should be handled here
//}
//数据结果
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits();
float maxScore = hits.getMaxScore();
ElasticSearchTools.logInfo(log, "查到结果数:"+totalHits+"最高得分:"+maxScore);
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
float score = hit.getScore();
String sourceAsString = hit.getSourceAsString();
//Map<String, Object> sourceAsMap = hit.getSourceAsMap();
ElasticSearchTools.logInfo(log, "分数:"+score+"结果:"+sourceAsString);
}
} catch (Exception e) {
e.printStackTrace();
}finally {
ElasticSearchTools.closeClientConnection(client);
}
return null;
}
2.聚合
为了方便理解,现在kibana里面写一个实例
GET /zhangsun/_search
{
"size": 0, //不显示查到的数据,只显示聚合结果
"aggs": {
"by_name": {
"terms": {
"field": "name.keyword",
"size": 10
},
"aggs": {
"avr_age": {
"terms": {
"field": "age",
"size": 10
}
}
}
}
}
}
运行结果:
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 5,
"max_score": 0,
"hits": []
},
"aggregations": {
"by_name": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "hjl",
"doc_count": 3,
"avr_age": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 21,
"doc_count": 1
},
{
"key": 22,
"doc_count": 1
},
{
"key": 25,
"doc_count": 1
}
]
}
},
{
"key": "zhangsun",
"doc_count": 2,
"avr_age": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 23,
"doc_count": 1
},
{
"key": 24,
"doc_count": 1
}
]
}
}
]
}
}
}
编写java代码
public String searchAPI(Elastic es) throws IOException {
RestHighLevelClient client = ElasticSearchTools.getClientConnection();
SearchRequest searchRequest = new SearchRequest(es.get_index()).types(es.get_type());
searchRequest.preference("_local");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//聚合查询
//按照name分组,并求个数和,再显示出前5条,聚合不能使用text类型的属性
TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_name").field("name.keyword").size(10);
//在上面的基础上再在每条记录后面追加一个属性average_age显示年龄平均值
aggregation.subAggregation(AggregationBuilders.avg("average_age").field("age"));
searchSourceBuilder.aggregation(aggregation);
//关联SearchSourceBuilder
searchRequest.source(searchSourceBuilder);
//搜索
SearchResponse searchResponse;
try {
searchResponse = client.search(searchRequest);
//状态结果
RestStatus status = searchResponse.status();
TimeValue took = searchResponse.getTook();
Boolean terminatedEarly = searchResponse.isTerminatedEarly();
boolean timedOut = searchResponse.isTimedOut();
ElasticSearchTools.logInfo(log, "状态码:"+status.toString()+"花费时间:"+took+"请求提前终止:"+terminatedEarly+"超时:"+timedOut);
//数据结果
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits();
float maxScore = hits.getMaxScore();
ElasticSearchTools.logInfo(log, "查到结果数:"+totalHits+"最高得分:"+maxScore);
//获取聚合结果
Aggregations aggregations = searchResponse.getAggregations();
//获取by_name聚合对应结果
Terms companyAggregation = (Terms) aggregations.get("by_name");
//对应上面bucket,有多条记录
List<? extends Bucket> buckets = companyAggregation.getBuckets();
for (Bucket bucket : buckets) {
String name = bucket.getKey().toString();
long count = bucket.getDocCount();
Avg averageAge=bucket.getAggregations().get("average_age");
double avg = averageAge.getValue();
ElasticSearchTools.logInfo(log,"name:"+name+",count:"+count+",avg_age:"+ String.valueOf(avg));
}
} catch (Exception e) {
e.printStackTrace();
}finally {
ElasticSearchTools.closeClientConnection(client);
}
return null;
}
在聚合查询的时候也可以通过searchSourceBuilder.query()先过滤再聚合。
异步++
3.scrollSerachAPI
在查询的结果数据量特别大的时候,我们需要分页显示数据,虽然from..size可以实现分页效果,但是也仅仅是显示一页。当我们需要所有结果时则使用scroll
首先下载官网提供的有11w条数据的json数据https://download.elastic.co/demos/kibana/gettingstarted/shakespeare_6.0.json。
然后通过指令:curl -X POST "localhost:9200/_bulk?pretty&refresh" -H "Content-Type: application/json" --data-binary "@json文件位置"将它创建。
首先我们通过kibana先看一下效果
POST /shakespeare/doc/_search?scroll=1m
{
"query": { "match_all": {}},
"_source": ["line_id","speaker"],
"size":10000,
"sort": ["line_id"]
}
控制台会打印前10000条数据,并且产生一个_scroll_id,将它复制到下面的_scroll_id字段里面
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : _scroll_id
}
多次执行这段DSL语句,会分别打印后面1w-2w、2w-3w的数据。因为数据是11w+条,在第13次执行时就会没有数据了。
下面介绍怎么使用JavaAPI操作scroll
public String scrollSearchAPI(Elastic es) throws IOException {
RestHighLevelClient client = ElasticSearchTools.getClientConnection();
//初始化,得到第一页数据以及scrollId
SearchRequest searchRequest = new SearchRequest("shakespeare");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.size(5000);
searchRequest.source(searchSourceBuilder);
//设置scroll
searchRequest.scroll(TimeValue.timeValueMinutes(1L));
SearchResponse searchResponse = client.search(searchRequest);
//获取scrollId
String scrollId = searchResponse.getScrollId();
SearchHit[] searchHits = searchResponse.getHits().getHits();
//根据scrollId找到后面的文档
while(searchHits != null && searchHits.length > 0) {
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
scrollRequest.scroll(TimeValue.timeValueSeconds(30));
SearchResponse searchScrollResponse = client.searchScroll(scrollRequest);
searchHits = searchScrollResponse.getHits().getHits();
ElasticSearchTools.logInfo(log, String.valueOf(searchScrollResponse.getHits().getHits().length));
}
//删除scrollId
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
ClearScrollResponse clearScrollResponse = client.clearScroll(clearScrollRequest);
boolean succeeded = clearScrollResponse.isSucceeded();
ElasticSearchTools.logInfo(log,succeeded?"success":"failed");
//没有进行异常处理,这里只是简单的关闭一下。
client.close();
return null;
}
异步++
其它API
获取本节点信息
public String infoAPI() throws IOException {
RestHighLevelClient client = ElasticSearchTools.getClientConnection();
MainResponse response=client.info();
String infoStr = JSONObject.toJSONString(response);
ElasticSearchTools.logInfo(log,infoStr);
client.close();
return infoStr;
}
结果
{
"available": true,
"build": {
"snapshot": false
},
"clusterName": {},
"clusterUuid": "N4uLCbI2Q262rh0OxqBoFg",
"fragment": false,
"nodeName": "node-2",
"version": {
"alpha": false,
"beta": false,
"build": 99,
"id": 6010199,
"luceneVersion": {
"bugfix": 0,
"major": 7,
"minor": 1,
"prerelease": 0
},
"major": 6,
"minor": 1,
"rC": false,
"release": true,
"revision": 1
}
}