

Samza 定期检查
Samza 提供流的容错处理:Samza 保证消息不会丢失,即使您的工作崩溃,如果机器死机,如果有网络故障或其他问题。为了提供这一保证,Samza 希望输入系统满足以下要求:
- 流可以划分成一个或多个分区。每个分区独立于其他分区,并且跨多台计算机进行复制(即使机器发生故障,该流仍然可用)。
- 每个分区由固定顺序的消息序列组成。每个消息都有一个偏移量,表示其在该顺序中的位置。消息总是在每个分区内依次消耗。
- Samza 作业可以从任何起始偏移开始消耗消息序列。
Kafka 符合这些要求,但也可以与其他消息代理系统一起实施。
如SamzaContainer一节中所述,您的任务的每个任务实例都会占用一个输入流的一个分区。每个任务对于每个输入流具有当前偏移量:要从该流分区读取的下一个消息的偏移量。每次从流中读取消息时,当前的偏移向前移动。
如果 Samza 容器出现故障,则需要重新启动(潜在地在另一台机器上),并恢复处理失败的容器。为了实现这一点,容器定期检查每个任务实例的当前偏移量。
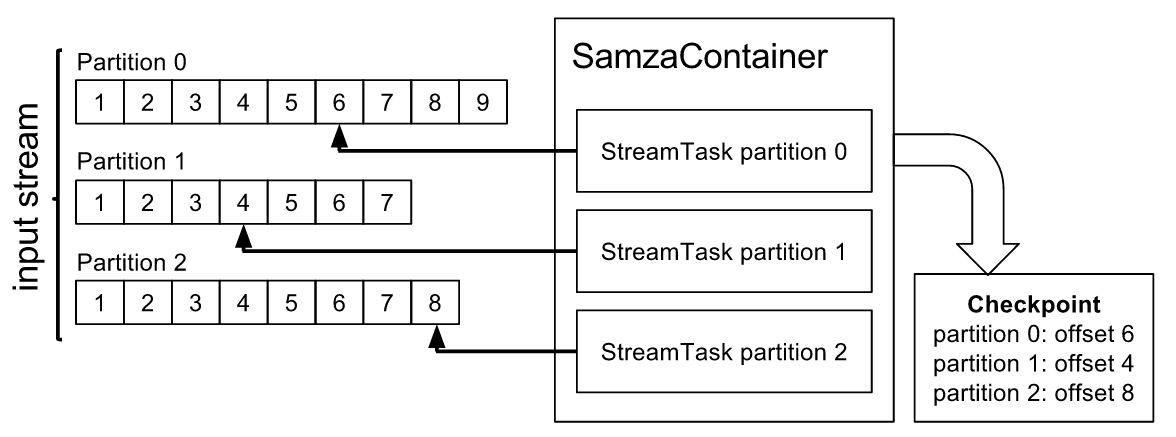
当 Samza 容器启动时,它会查找最新的检查点,并从检查点偏移开始消费消息。如果上一个容器意外失败,则最近的检查点可能稍微偏离当前的偏移量(即,自上次检查点写入以来,该作业可能已经消耗了一些更多的消息),但是我们无法确定。在这种情况下,该作业可能再次处理几个消息。
这种保证被称为至少一次处理:Samza 确保您的工作不会错过任何消息,即使容器需要重新启动。但是,当重新启动容器时,您的作业可能会多次看到相同的消息。我们计划在 Samza 的未来版本中解决这个问题,但现在只需要注意一些事情:例如,如果您正在计算页面浏览量,强制杀死的容器可能导致事件略微过度计数。您可以以更低的性能成本更频繁地检查点来减少重复。
为了使检查站有效,他们需要写在他们能够在故障中生存的地方。Samza 允许您将检查点写入文件系统(使用 FileSystemCheckpointManager ),但是如果机器发生故障,并且需要在另一台机器上重新启动该容器,则不起作用。最常见的配置是使用 Kafka 作为检查点。您可以通过以下作业配置启用此功能:
# The name of your job determines the name under which checkpoints will be stored
job.name=example-job
# Define a system called "kafka" for consuming and producing to a Kafka cluster
systems.kafka.samza.factory=org.apache.samza.system.kafka.KafkaSystemFactory
# Declare that we want our job's checkpoints to be written to Kafka
task.checkpoint.factory=org.apache.samza.checkpoint.kafka.KafkaCheckpointManagerFactory
task.checkpoint.system=kafka
# By default, a checkpoint is written every 60 seconds. You can change this if you like.
task.commit.ms=60000在这种配置中,Samza 将检查点写入一个名为 “__samza_checkpoint_
有时只能对某些输入流使用检查点,但不适用于其他输入流。在这种情况下,您可以告诉 Samza 忽略特定流名称的任何检查点偏移量:
# Ignore any checkpoints for the topic "my-special-topic"
systems.kafka.streams.my-special-topic.samza.reset.offset=true
# Always start consuming "my-special-topic" at the oldest available offset
systems.kafka.streams.my-special-topic.samza.offset.default=oldest下表说明了这些配置参数的含义:
| 参数名称 | 值 | 含义 |
|---|---|---|
|
系统。<系统>。
流。<流>。
samza.reset.offset
|
假(默认) | 容器启动时,从上次检查点恢复处理 |
| 真正 | 忽略检查点(假装没有检查点存在) | |
|
系统。<系统>。
流。<流>。
samza.offset.default
|
即将到来(默认) | 当容器启动并且没有检查点(或检查点被忽略)时,仅处理在作业启动后发布的消息,但没有旧消息 |
| 最老的 | 当容器启动并且没有检查点(或检查点被忽略)时,跳回到系统中最旧的可用消息,并从该点开始消耗所有消息(很可能这意味着先前已经看到的消息的重复处理) |
请注意,上述示例配置使您的任务在每次启动容器时从最早的偏移量开始消耗。这在您的任务中需要从输入流中的源数据重建时具有某些内存状态时非常有用。如果您以这种方式使用流,您可能还会发现引导流很有用。
手动操作检查点
如果要对作业的消费者偏移进行一次性更改,例如强制使用新版本的代码再次处理旧消息,则可以使用 CheckpointTool 来检查和操作作业的检查点。该工具包含在 Samza 的开源代码存储库中。
要检查工作的最新检查点,您需要指定作业的配置文件,以便该工具知道要处理的作业:
samza-example/target/bin/checkpoint-tool.sh
--config-path=file:///path/to/job/config.properties此命令以属性文件格式打印出最新的检查点。您可以将输出保存到文件中,并根据需要进行编辑。例如,要跳回到最早可能的时间点,您可以将所有偏移量设置为0.然后可以将该属性文件反馈到 checkpoint-tool.sh 并保存修改的检查点:
samza-example/target/bin/checkpoint-tool.sh
--config-path=file:///path/to/job/config.properties
--new-offsets=file:///path/to/new/offsets.properties请注意,Samza 仅在容器启动时读取检查点。为了使检查点更改生效,您需要先停止作业,然后保存修改的偏移量,然后再次启动作业。如果在作业正在运行时写一个检查点,那么它很有可能没有效果。
检查点回调
目前 Samza 负责所有系统的检查点。但是有一些用例可能需要通知消费者我们制作的每个检查点。以下是几个例子:
- Samza 无法正确或有效地进行检查点。一个这样的情况是 Samza 没有做分区。在这种情况下,容器不知道它负责哪个 SSP,因此不能检查它们。一个实际的例子可能是一个依赖自动平衡的高级卡夫卡消费者进行分区的系统。
- 消费者自身需要控制检查点偏移的系统。某些系统不支持 seek()操作(不可重放),但它们依赖于传递消息的 ACK。例如可以是 Kinesis 消费者。Kinesis 库在* process()* call(推系统)中提供检查点回调。在处理记录之后需要调用此回调。这只能由消费者本身来完成。
- 使用检查点/偏移量信息进行某些维护操作的系统。该信息可用于实施智能保留策略(在消耗完所有数据后将所有数据删除)。
为了使用检查点回调,SystemConsumer 需要实现 CheckpointListener 接口:
public interface CheckpointListener {
void onCheckpoint(Map offsets);
} 对于实现此接口的 SystemConsumers,Samza 将每次在 OffsetManager 检查点调用 onCheckpoint()回调。检查点是根据任务完成的,“偏移”是任务的 Samza 检查点的所有偏移量,这些是在重新启动时传递给消费者的偏移量。请注意,回调将在检查点之后发生,并且不是原子的。
