

Samza Container
SamzaContainer 负责管理一个或多个 StreamTask 实例的启动,执行和关闭。每个 SamzaContainer 通常作为一个独立的 Java 虚拟机运行。Samza 工作可以由几个可能运行在不同机器上的 SamzaContainers 组成。
当 SamzaContainer 启动时,它执行以下操作:
- 获取消耗的每个输入流分区的上次检查点偏移量
- 为其消耗的每个输入流分区创建一个“阅读器”线程
- 开始指标报告员报告指标
- 启动一个检查点计时器,以便每隔一段时间保存任务的输入流偏移量
- 启动窗口计时器以触发您的任务窗口方法(如果已定义)
- 为每个输入流分区实例化并初始化一次StreamTask
- 启动一个事件循环,从输入流读取器线程接收消息,并将它们提供给您的StreamTasks
- 在每个步骤中通知生命周期侦听器
我们从中间开始,通过 StreamTask 的实例化。本文档的以下部分涵盖了其他步骤。
任务和分区
当容器启动时,它会创建您编写的任务类的实例。如果任务类实现了InitableTask接口,SamzaContainer 也将调用 init()方法。
/** Implement this if you want a callback when your task starts up. */
public interface InitableTask {
void init(Config config, TaskContext context);
}默认情况下,创建任务类的实例数取决于作业输入流中的分区数。如果您的 Samza 作业有十个分区,您的任务类将有十个实例:每个分区一个。第一个任务实例将接收所有分区的消息,第二个实例将接收分区二的所有消息,依此类推。
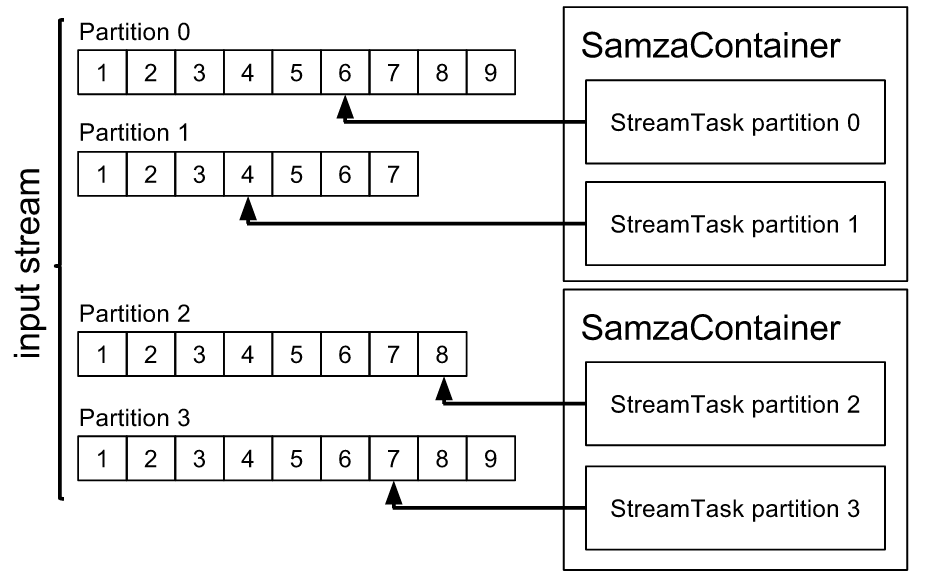
输入流中的分区数由您所消费的系统决定。例如,如果您的输入系统是 Kafka,则可以在命令行中创建主题或在 Kafka 的服务器属性文件中使用 num.partition 指定分区数。
如果 Samza 作业有多个输入流,则 Samza 作业的任务实例数是所有输入流中最大分区数。例如,如果 Samza 作业正在从 PageViewEvent(12个分区)和 ServiceMetricEvent(14个分区)读取,则 Samza 作业将具有14个任务实例(编号为0到13)。任务实例12和13只接收来自 ServiceMetricEvent 的事件,因为没有相应的 PageViewEvent 分区。
使用这种将输入流分配给任务实例的默认方法,Samza 正在以其分区作为键对输入流上的分组操作进行有效的执行。通过实施新的SystemStreamPartitionGrouper和工厂以及配置作业以通过 job.systemstreampartition.grouper.factory 配置值使用它来实现对输入流分区进行分组的其他策略。
Samza 提供了上述讨论的每个分区分片器以及 GroupBySystemStreamPartitionGrouper,它为每个输入流分区提供一个单独的任务类实例,有效地通过输入流本身进行分组。这提供了可以使用多少个容器来处理这些输入流的最大可扩展性,并且适用于不需要输入流分组的非常高容量的作业。
考虑到上述 PageViewEvent 分区12路和 ServiceMetricEvent 分区方式的示例,GroupBySystemStreamPartitionGrouper 将创建12 + 14 = 26个任务实例,然后将分布在配置的容器数量上,如下所述。
请注意,一旦使用特定的 SystemStreamPartitionGrouper 启动作业,该作业正在使用状态或检查点,则不可能在后续作业启动时更改该分组,因为在新的分组方法中以前的检查点和状态信息可能不正确。
容器和资源分配
虽然任务实例的数量是固定的 - 由输入分区的数量确定 - 您可以配置要用于作业的容器数量。如果使用YARN,容器数决定了哪些CPU和内存资源分配给您的作业。
如果输入流上的数据量很小,那么只能使用一个 SamzaContainer 就足够了。在这种情况下,Samza 仍会为每个输入分区创建一个任务实例,但所有这些任务都在同一容器中运行。另一方面,您可以创建与分区一样多的容器,Samza 将为每个容器分配一个任务实例。
每个 SamzaContainer 设计为使用一个CPU内核,因此它使用单线程事件循环执行。在 SamzaContainer 中创建自己的线程是不可取的。如果需要更多的并行性,请将您的工作配置为使用更多的容器。
您的作业中的任何状态都属于任务实例,而不是容器。这是 Samza 可扩展性的关键设计决策:随着您的工作资源需求的增长和缩小,您可以简单地增加或减少容器数量,但是任务实例的数量保持不变。当您向上或向下扩展时,每个任务实例仍然保持相同的状态。任务实例可能从一个容器移动到另一个容器,并且由 Samza 管理的任何持久状态将随之移动。这样就可以使作业的处理语义保持不变,即使您更改了作业的并行性。
加入多个输入流
如果您的工作有多个输入流,Samza 提供了一个简单而强大的机制来加入来自不同流的数据:每个任务实例都从每个输入流的一个分区接收消息。例如,假设您有两个输入流A和B,每个具有四个分区。Samza 创建四个任务实例来处理它们,并按如下所示分配分区:
| 任务实例 | 消耗流分区 |
|---|---|
| 0 | 流A分区0,流B分区0 |
| 1 | 流A分区1,流B分区1 |
| 2 | 流A分区2,流B分区2 |
| 3 | 流A分区3,流B分区3 |
因此,如果您希望不同流中的两个事件由同一个任务实例处理,则需要确保将其发送到相同的分区号。您可以通过在发送消息时使用相同的分区键来实现此目的。状态管理部分详细讨论了连接流。
所有这一切都有一个警告:Samza 目前假设一个流的分区计数永远不会改变。不支持分区拆分或重新分区。如果输入流具有 N 个分区,则预计它始终具有并且将始终具有N个分区。如果要重新分区流,则可以编写从流中读取消息的作业,并将其写入具有所需数量分区的新流。例如,您可以从 PageViewEvent 读取消息,并将它们写入 PageViewEventRepartition。
广播流
0.10.0之后,Samza 支持广播流。您可以通过附加哈希标记以及分区号或分区号范围来将某些流中的分区分配给所有任务。例如,您希望所有任务可以从称为广播流-1的流中消耗分区0和1,并从称为广播流-2的流中分配2。您现在可以配置:
task.broadcast.inputs=yourSystem.broadcast-stream-1#[0-1], yourSystem.broadcast-stream-2#2如果使用 “[]”,则指定分区的范围。
