

Samza 结构
Samza 由三层组成:
- 流媒体层。
- 一个执行层。
- 处理层。
Samza 为所有三层提供了即时支持。
这三个组合在一起形成Samza:
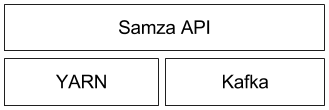
该架构遵循与 Hadoop 类似的模式(它也使用 YARN 作为执行层,用于存储的 HDFS 和 MapReduce 作为处理 API):
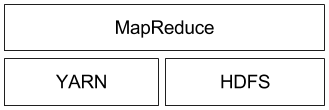
在深入分析这三个层次之前,应该注意的是,Samza 的支持不仅限于 Kafka 和 YARN。Samza 的执行和流式传输层都是可插拔的,并允许开发人员如果愿意实施替代方案。
Kafka
Kafka 是一个分布式的 pub / sub 和消息队列系统,它提供至少一次消息传递保证(即系统保证没有消息丢失,但在某些故障情况下,消费者可能会多次收到相同的消息),并且高度可用的分区(即,即使机器掉电,流的分区仍然可用)。
在 Kafka ,每个流被称为主题。每个主题都被分割并复制到多台名为broker(代理)的计算机上。当producer(生产者)向主题发送消息时,它提供一个密钥,用于确定消息应发送到哪个分区。Kafka代理收到并存储生产者发送的消息。然后,Kafka用户可以通过订阅主题的所有分区上的消息来读取主题。
卡夫卡有一些有趣的属性:
- 具有相同密钥的所有消息都保证位于相同的主题分区中。这意味着如果您想要读取特定用户标识的所有消息,则只需要从包含用户标识的分区读取消息,而不是整个主题(假设用户ID被用作密钥)。
- 主题分区是到达顺序的消息序列,因此您可以使用单调增加的偏移量(如数组中的索引)来引用分区中的任何消息。这意味着代理不需要跟踪特定用户看到哪些消息 - 用户可以通过存储其已经处理的最后一个消息的偏移来跟踪自身。然后知道每个具有比当前偏移量偏移较小的消息已经被处理; 每个具有较高偏移量的消息尚未被处理。
YARN
YARN(另一个资源谈判者)是 Hadoop 的下一代群集调度程序。它允许您在一组机器中分配一些容器(进程),并对它们执行任意命令。
当应用程序与 YARN 进行交互时,它看起来像这样:
- 应用程序:我想在具有512MB内存的两台机器上运行命令 X.
- YARN:很酷,你的代码在哪里?
- 应用程序:http://path.to.host/jobs/download/my.tgz
- YARN:我在node-1.grid和node-2.grid上运行你的工作。
Samza 使用 YARN 来管理部署,容错,日志记录,资源隔离,安全性和局部性。
YARN建筑
YARN 有三个重要的部分:ResourceManager,NodeManager和ApplicationMaster。在YARN网格中,每台机器都运行一个NodeManager,它负责在该机器上启动进程。ResourceManager 与所有 NodeManager 通信,告诉他们要运行什么。如果应用程序希望在群集上运行某些内容,则可以与 ResourceManager 通信。第三部分,ApplicationMaster 实际上是在 YARN 集群中运行的特定于应用程序的代码。它负责管理应用程序的工作负载,请求容器(通常为 UNIX 进程),以及在其中一个容器发生故障时处理通知。
Samza 和 YARN
Samza 提供了一个YARN ApplicationMaster 和一个 YARN 作业运行器开箱即用。Samza 和 YARN 的集成在下图中概述(不同的颜色表示不同的主机):
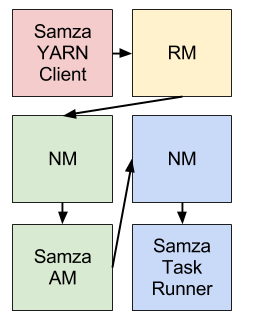
当 Samza 的客户想要开始一个新的 Samza 工作时,Samza 客户会与 YARN RM 谈话。YARN RM 与 YARN NM 谈话,为 Samza 的 ApplicationMaster 在群集上分配空间。一旦 NM 分配空间,它将启动 Samza AM。在 Samza AM 启动之后,它向 YARN RM 询问一个或多个 YARN 容器运行SamzaContainers。再次,RM 与 NM 一起为容器分配空间。一旦分配空间,NM 将启动 Samza 容器。
Samza
Samza 使用 YARN 和 Kafka 为逐级流处理和分区提供了一个框架。一切,放在一起,看起来像这样(不同的颜色表示不同的主机):
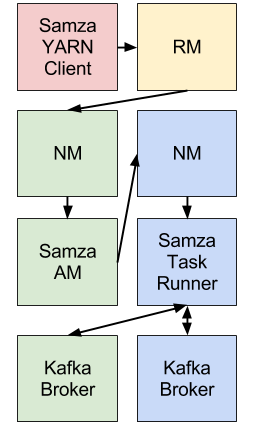
Samza 客户端使用 YARN 运行 Samza 工作:YARN 启动并监督一个或多个SamzaContainers,您的处理代码(使用StreamTask API)在这些容器内运行。Samza StreamTasks 的输入和输出来自 Kafka 代理(通常)位于与 YARN NMs 相同的计算机上。
例
让我们来看一个真实的例子:假设我们要计算页面浏览量。在 SQL 中,你会写下如下:
SELECT user_id, COUNT(*) FROM PageViewEvent GROUP BY user_id虽然 Samza 现在不支持 SQL,但这个想法是一样的。计算此查询需要两个作业:一个用户 ID 分组消息,另一个进行计数。
在第一个作业中,通过将具有相同用户 ID 的所有消息发送到中间主题的相同分区来完成分组。您可以通过使用用户 ID 作为第一个作业发出的消息的关键字来执行此操作,并将此密钥映射到中间主题的一个分区(通常通过使用键的散列值 mod 分区数)。第二个工作消耗中间话题。第二个任务中的每个任务都占用中间主题的一个分区,即用户 ID 子集的所有消息。该任务对其分区中的每个用户 ID 具有计数器,并且每当任务接收到具有特定用户 ID 的消息时,相应的计数器递增。
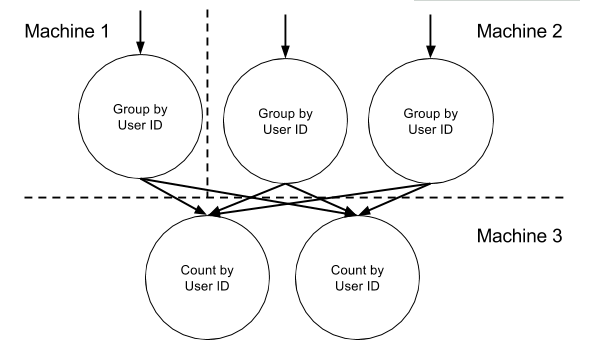
如果您熟悉 Hadoop,您可以将其识别为 Map / Reduce 操作,其中每个记录与映射器中的特定键相关联,具有相同键的记录由框架组合在一起,然后在减少步骤中计数。Hadoop 和 Samza之间的区别在于 Hadoop 在固定输入上运行,而 Samza 则使用无限流数据。
Kafka 接收第一个作业发出的消息并将其缓冲在磁盘上,分布在多台计算机上。这有助于使系统容错:如果一台计算机发生故障,则不会丢失任何消息,因为它们已被复制到其他计算机。而且如果第二个工作出现任何原因缓慢或停止使用消息,则第一个工作不受影响:磁盘缓冲区可以吸收第一个工作中积压的消息,直到第二个工作重新启动。
通过分割主题,通过将流处理分解为在多台计算机上运行的作业和并行任务,Samza 可以以非常高的消息吞吐量扩展到流。通过使用 YARN 和 Kafka,Samza 可以实现容错:如果进程或计算机出现故障,则会在另一台计算机上自动重新启动,并从停止点继续处理消息。
