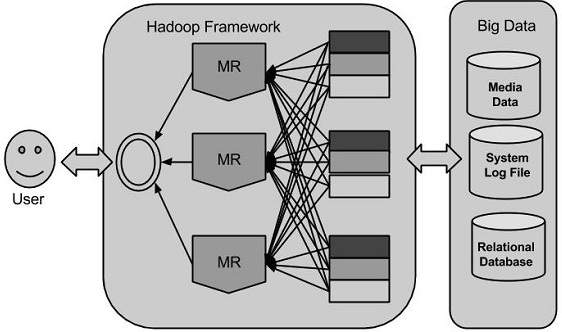
Hadoop 大数据解决方案
传统方法
在这种方法中,企业将具有存储和处理大数据的计算机。这里的数据将存储在RDBMS如Oracle数据库,MS SQL Server或DB2和复杂的软件可以写入与数据库交互,处理所需的数据,并将其呈现给用户进行分析。
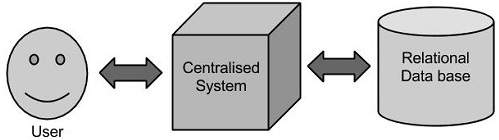
局限性
这种方法在我们的标准数据库服务器可以容纳的数据量较少,或者正在处理数据的处理器的限制时运行良好。但是,当涉及到处理大量的数据时,通过传统的数据库服务器处理这样的数据真是一个单调乏味的任务。
谷歌的解决方案
Google使用称为MapReduce的算法解决了这个问题。该算法将任务分成小部分,并将这些部分分配给通过网络连接的许多计算机,并收集结果以形成最终结果数据集。
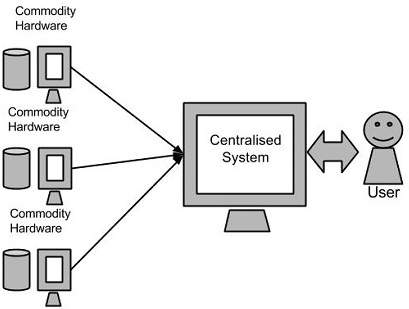
上图显示了各种商品硬件,可能是单CPU机或具有更高容量的服务器。
Hadoop
Doug Cutting,Mike Cafarella和团队采用了Google提供的解决方案,并于2005年开始了一个名为HADOOP的开源项目,Doug在他儿子的玩具大象之后命名了它。现在Apache Hadoop是Apache Software Foundation的注册商标。
Hadoop使用MapReduce算法运行应用程序,其中数据在不同的CPU节点上并行处理。总之,Hadoop框架足以开发能够在计算机集群上运行的应用程序,并且他们可以对大量数据执行完整的统计分析。