

Hadoop 简介
Hadoop是一个用Java编写的Apache开源框架,允许使用简单的编程模型跨计算机集群分布式处理大型数据集。Hadoop框架工作的应用程序在跨计算机集群提供分布式存储和计算的环境中工作。Hadoop旨在从单个服务器扩展到数千个机器,每个都提供本地计算和存储。Hadoop可运行于一般的商用服务器上,具有高容错、高可靠性、高扩展性等特点,特别适合写一次,读多次的场景
适合
- 大规模数据
- 流式数据(写一次,读多次)
- 商用硬件(一般硬件)
不适合
- 低延时的数据访问
- 大量的小文件
- 频繁修改文件(基本就是写1次)
Hadoop架构
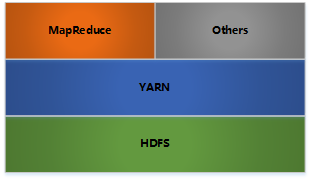
- HDFS: 分布式文件存储
- YARN: 分布式资源管理
- MapReduce: 分布式计算
- Others: 利用YARN的资源管理功能实现其他的数据处理方式
内部各个节点基本都是采用Master-Woker架构
Hadoop框架包括以下四个模块:
Hadoop Common: 这些是其他Hadoop模块所需的Java库和实用程序。这些库提供文件系统和操作系统级抽象,并包含启动Hadoop所需的Java文件和脚本。
Hadoop YARN: 这是一个用于作业调度和集群资源管理的框架。
Hadoop Distributed File System (HDFS™): 分布式文件系统,提供对应用程序数据的高吞吐量访问。
Hadoop MapReduce:这是基于YARN的用于并行处理大数据集的系统。
我们可以使用下面的图来描述这四个组件在Hadoop框架中可用。

自2012年以来,“Hadoop”这个术语通常不仅指上述基本模块,而且还指向可以安装在Hadoop之上或之上的附加软件包的收集,例如Apache Pig,Apache Hive,Apache HBase,Apache Spark等。
MapReduce
Hadoop MapReduce是一个软件框架,用于轻松编写应用程序,以可靠,容错的方式在大型集群(数千个节点)的商用硬件上并行处理大量数据。
术语MapReduce实际上指的是Hadoop程序执行的以下两个不同任务:
The Map Task: 术语MapReduce实际上指的是Hadoop程序执行的以下两个不同任务:
The Reduce Task: 此任务将map任务的输出作为输入,并将这些数据元组合并为较小的元组集合。 reduce任务总是在map任务之后执行。
通常输入和输出都存储在文件系统中。该框架负责调度任务,监视它们并重新执行失败的任务。
MapReduce框架由每个集群节点的单个主JobTracker和一个从属TaskTracker组成。主机负责资源管理,跟踪资源消耗/可用性以及调度从机上的作业组件任务,监视它们并重新执行失败的任务。从属TaskTracker按主控器指示执行任务,并定期向主控器提供任务状态信息。
JobTracker是Hadoop MapReduce服务的单点故障,这意味着如果JobTracker关闭,所有正在运行的作业都将停止。
Hadoop分布式文件系统
Hadoop可以直接与任何可安装的分布式文件系统(如本地FS,HFTP FS,S3 FS等)一起工作,但Hadoop使用的最常见的文件系统是Hadoop分布式文件系统(HDFS)。
Hadoop分布式文件系统(HDFS)基于Google文件系统(GFS),并提供一个分布式文件系统,该系统设计为在大型集群(数千台计算机)上运行小型计算机机器以可靠,容错方式。
HDFS使用主/从架构,其中主节点由管理文件系统元数据的单个NameNode和存储实际数据的一个或多个从节点DataNode组成。
HDFS命名空间中的文件被拆分为几个块,这些块存储在一组DataNode中。 NameNode决定块到DataNode的映射。DataNodes负责与文件系统的读写操作。它们还根据NameNode给出的指令来处理块创建,删除和复制。
HDFS提供了一个类似任何其他文件系统的shell,并且有一个命令列表可用于与文件系统交互。这些shell命令将在单独的章节以及适当的示例中介绍。
Hadoop如何工作?
阶段 1
用户/应用程序可以通过指定以下项目来向Hadoop(hadoop作业客户端)提交作业以获取所需的进程:
分布式文件系统中输入和输出文件的位置。
java类以jar文件的形式包含map和reduce函数的实现。
通过设置作业的不同参数来配置作业。
阶段 2
Hadoop作业客户端然后将作业(jar /可执行文件等)和配置提交给JobTracker,JobTracker然后承担将软件/配置分发给从属的责任,Hadoop作业客户端然后将作业(jar /可执行文件等)和配置提交给JobTracker,JobTracker然后承担将软件/配置分发给从属的责任,
阶段 3
不同节点上的TaskTracker根据MapReduce实现执行任务,reduce函数的输出存储在文件系统上的输出文件中。
Hadoop的优势
Hadoop框架允许用户快速编写和测试分布式系统。它是高效的,它自动分配数据和工作在整个机器,反过来,利用CPU核心的底层并行性。
Hadoop不依赖硬件来提供容错和高可用性(FTHA),相反Hadoop库本身设计用于检测和处理应用程序层的故障。
服务器可以动态添加或从集群中删除,Hadoop继续运行而不中断。
Hadoop的另一个大的优点是,除了开源之外,它在所有平台上兼容,因为它是基于Java的。
